Beginners Guide to Columnar File Formats in Spark and Hadoop


image by gdtography
Hire me to supercharge your Hadoop and Spark projects
I help businesses improve their return on investment from big data projects. I do everything from software architecture to staff training. Learn More
This article is a follow-up to my guide to Spark and Hadoop file formats, which is a good place to start if you don’t know anything about big data file formats yet.
What does ‘columnar file format’ actually mean?
People throw this term around a lot, but I don’t think it is always clear exactly what this means in practice.
The textbook definition is that columnar file formats store data by column, not by row. CSV, TSV, JSON, and Avro, are traditional row-based file formats. Parquet, and ORC file are columnar file formats.
Let’s illustrate the differences between these two concepts using some example data and a simple illustrative columnar file format that I just invented.
Here’s a data schema for a ‘people’ dataset, it’s pretty straight forward:
{
id: Integer,
first_name: String,
last_name: String,
age: Integer,
cool: Boolean,
favorite_fruit: Array[String]
}
Data in Row Format
We could represent this dataset in several formats, for example here is a JSON flat file:
{"id": 1, "first_name": "Matthew", "last_name": "Rathbone", "age": 19, "cool": true, "favorite_fruit": ["bananas", "apples"]}
{"id": 2, "first_name": "Joe", "last_name": "Bloggs", "age": 102, "cool": true, "favorite_fruit": null}
Here’s the same data in everyone’s favorite format, CSV
1, Matthew, Rathbone, 19, True, ['bananas', 'apples']
2, Joe, Bloggs, 102, True,
In both of these formats, each line of the file contains a full row of data. This is how humans like to think about data, neat rows lined up, easy to scan, easy to edit in Excel, easy to read in a terminal or text editor.
Data in Columnar Format
I’m going to introduce a (fake) columnar file-format for illustrative purposes, let’s call it CCSV (Columnar CSV).
Each line of our CCSV file has the following content:
Field Name/Field Type/Number of Characters:[data in csv format]
Here’s the same data in CCSV:
ID/INT/3:1,2
FIRST_NAME/STRING/11:Matthew,Joe
LAST_NAME/STRING/15:Rathbone,Bloggs
AGE/INT/6:19,102
COOL/BOOL/3:1,1
FAVORITE_FRUIT/ARRAY[STRING]/19:[bananas,apples],[]
Notice that all the names, ages, and fruits are stored next to each other, not alongside other data from the same record. To stop each column section getting too big, CCSV will repeat this pattern every 1000 records. So a 10,000 record file will contain 10 sections of grouped column data.
Can humans easily read CCSV files? Sort of, but you’d be hard pressed to assemble a coherent view of the data if you opened it in Excel. However CCSV has a couple of useful properties that make it better for computers, and I’ll talk about those now.
Benefits of Columnar Formats
Read-Optimization
Let me pretend I want to run a SQL query against this data, for example:
SELECT COUNT(1) from people where last_name = "Rathbone"
With a regular CSV a SQL engine would have to scan every row, parse each column, extract the last_name value, then count all Rathbone values that it sees.
In CCSV, the SQL engine can skip past the first two fields and simply scan line 3, which contains all the last name values available.
Why is that good? Well now the SQL engine is only processing around 1/6 of the data, so CCSV just delivered a (theoretical and totally unsubstantiated) 600% performance improvement vs regular CSV files.
Imagine the same gains against a petabyte-scale dataset. It is not hard to imagine columnar file format optimizations saving a tonne of processing power (and money) compared to regular JSON datasets. This is the core value of columnar file formats.
Of course, in reality there is more work that CCSV would need to do to be a viable file format, but that is getting a little into the weeds, so I will not cover those topics here.
Compression Improvements
Storing like-data together also has advantages for compression codecs. Many compression codecs (including GZIP and Snappy) have a higher compression-ratio when compressing sequences of similar data. By storing records column-by-column, in many cases each section of column data will contain similar values — that makes it ripe for compression. In fact, each column could be compressed independently of the others to optimize this further.
Negatives of Columnar Formats
The biggest negative of columnar formats is that re-constructing a complete record is slower and requires reading segments from each row, one-by-one. It is for this reason that columnar-file-formats initially hit their groove for analytics-style workflows, rather than Map/Reduce style workflows — which by default operate on whole rows of data at a time.
For real columnar file formats (like Parquet), this downside is minimized by some clever tricks like breaking the file up into ‘row groups’ and building extensive metadata, although for particularly wide datasets (like 200+ columns), the speed impact can be fairly significant.
The other downside, is that they are more CPU and ram intensive to write, as the file writer needs to collect a whole bunch of metadata, and reorganize the rows before it can write the file.
As an aside - I still almost always recommend still using a columnar file format, it’s just so useful to be able to quickly peek into a file and gather some simple metrics.
Real Columnar File Formats
Now you know what to expect, let’s quickly look at a real file format, Parquet. There are much more comprehensive guides to parquet, I recommend reading the official parquet docs in particular to get a sense of how the whole thing works.
Here’s a diagram from the Parquet docs showing Parquet file layout. It’s a little overwhelming to look at, but I think a key takeaway is the importance of data organization and metadata. I’m only showing an overview diagram here, but the docs are comprehensive while also being accessible-enough if you sort of know what is going on (and you probably do by this point!).
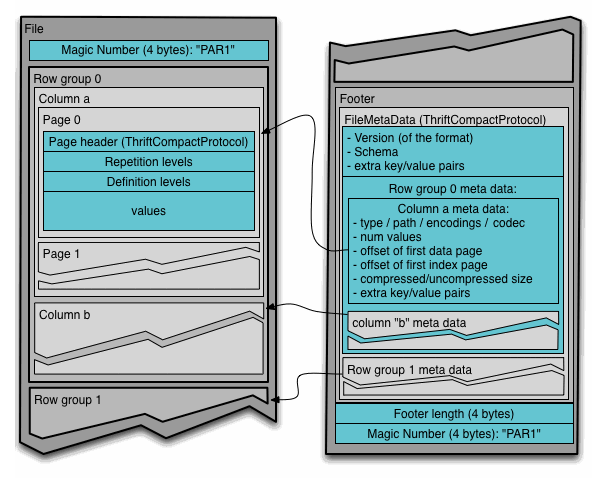
Columnar Format Takeaways
For Spark, Spark SQL, Hive, Impala, and other similar technologies, Columnar-storage of data can yield a 100x, and sometimes a 1000x performance improvement, especially for sparse queries on very wide datasets. While complex, the files are optimized for computers, and while this makes them hard to read as a human, they really do feel like a big leap forwards when compared with formats like JSON or Avro.
Wow, you made it all the way here?
Thanks for reading to the very bottom! I guess you’re deep into some big data work if you made it all this way. If you ever need to bounce ideas off of someone or get some advice on something you are working on, send me an email - matthew (at) rathbonelabs (dot com). I love talking about big data with smart folks
For more reading on file formats check out some of my other articles:
PS, I’m available to hire to build your big data analytics pipelines, deliver your cloud migrations, and design your dev-ops systems.
