Should you use Parquet?


image by Miltiadis Fragkidis
Hire me to supercharge your Hadoop and Spark projects
I help businesses improve their return on investment from big data projects. I do everything from software architecture to staff training. Learn More
If you’ve read my introduction to Hadoop/Spark file formats, you’ll be aware that there are multiple ways to store data in HDFS, S3, or Blob storage, and each of these file types have different properties that make them good (or bad) at different things.
While this article is not a technical deep-dive, I’m going to give you the rundown on why (and how) you should use Parquet over another popular format, Avro.
What is Parquet?
At a high level, parquet is a file format for storing structured data. For example, you can use parquet to store a bunch of records that look like this:
{
id: Integer,
first_name: String,
last_name: String,
age: Integer,
cool: Boolean,
favorite_fruit: Array[String]
}
You could, in fact, store this data in almost any file format, a reader-friendly way to store this data is in a CSV or TSV file. Here’s what some data in this schema might look like in a CSV format:
1, Matthew, Rathbone, 19, True, ['bananas', 'apples']
2, Joe, Bloggs, 102, True,
In a JSON flat file, we’d store each row as a JSON object:
{"id": 1, "first_name": "Matthew", "last_name": "Rathbone", "age": 19, "cool": true, "favorite_fruit": ["bananas", "apples"]}
{"id": 2, "first_name": "Joe", "last_name": "Bloggs", "age": 102, "cool": true, "favorite_fruit": null}
In contrast, here’s a screenshot of the same data in a illustrative columnar file format I call Columnar CSV (CCSV):
ID/INT/3:1,2
FIRST_NAME/STRING/11:Matthew,Joe
LAST_NAME/STRING/15:Rathbone,Bloggs
AGE/INT/6:19,102
COOL/BOOL/3:1,1
FAVORITE_FRUIT/ARRAY[STRING]/19:[bananas,apples],[]
Confused about Columnar file formats? Read my introduction to columnar file formats before going any further
Totally different right? Parquet goes a step further - it is a binary-based format, not a text-based format. Don’t worry, there are plenty of tools you can use to inspect and read Parquet files and even export the results to good old JSON. For example Parquet Tools
Parquet Cares About Your Schema
One limitation of CSV/TSV data is that you don’t know what the exact schema is supposed to be, or the desired type of each field.
Using our example above, without the schema, should the ‘True’ values be cast to boolean? How can we be sure without knowing the schema beforehand?
JSON improves upon CSV as each row provides some indication of schema, but without a special header-row, there’s no way to derive a schema for every record in the file, and it isn’t always clear what type a ‘null’ value should be interpreted as.
Avro and Parquet on the other hand understand the schema of the data they store. When you write a file in these formats, you need to specify your schema. When you read the file back, it tells you the schema of the data stored within. This is super useful for a framework like Spark, which can use this information to give you a fully formed data-frame with minimal effort.
Let’s talk about Parquet vs Avro
On their face, Avro and Parquet are similar they both write the schema of their enclosed data in a file header and deal well with schema drift (adding/removing columns). They’re so similar in this respect that Parquet even natively supports Avro schemas, so you can migrate your Avro pipelines to Parquet storage in a pinch.
The big difference in the two formats is that Avro stores data BY ROW, and parquet stores data BY COLUMN..
- Oh hai! Don’t forget about my guide to columnar file formats if you want to learn more about them
Benefits of Parquet over Avro
To recap on my columnar file format guide, the advantage to Parquet (and columnar file formats in general) are primarily two fold:
- Reduced Storage Costs (typically) vs Avro
- 10-100x improvement in reading data when you only need a few columns
I cannot overstate the benefit of a 100x improvement in record throughput. It provides a truly massive and fundamental improvement to data processing pipelines that it is very hard to overlook.
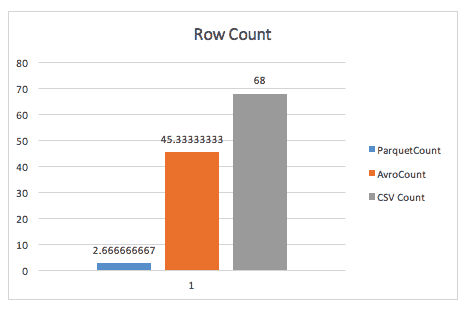
Here’s an illustration of this benefit from a Cloudera case study back in 2016 on a small dataset of less than 200GB.
When simply counting rows, Parquet blows Avro away, thanks to the metadata parquet stores in the header of row groups.
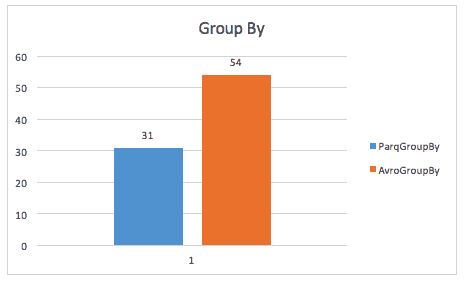
When running a group-by query, parquet is still almost 2x faster (although I’m unsure of the exact query used here).
The same case study also finds improvements in storage space, and even in full-table scans, likely due to Spark having to scan a smaller datasize.
Benefits of Avro over Parquet
I have heard some folks argue in favor of Avro vs Parquet. Such arguments are typically based around two points:
- When you are reading entire records at once, Avro wins in performance.
- Write-time is increased drastically for writing Parquet files vs Avro files
While these two points are valid, they are minor footnotes against Parquet performance improvements overall. There are many benchmarks available online for Avro vs Parquet, but let me draw a chart from a Hortonworks 2016 presentation comparing file format performance in various situations.
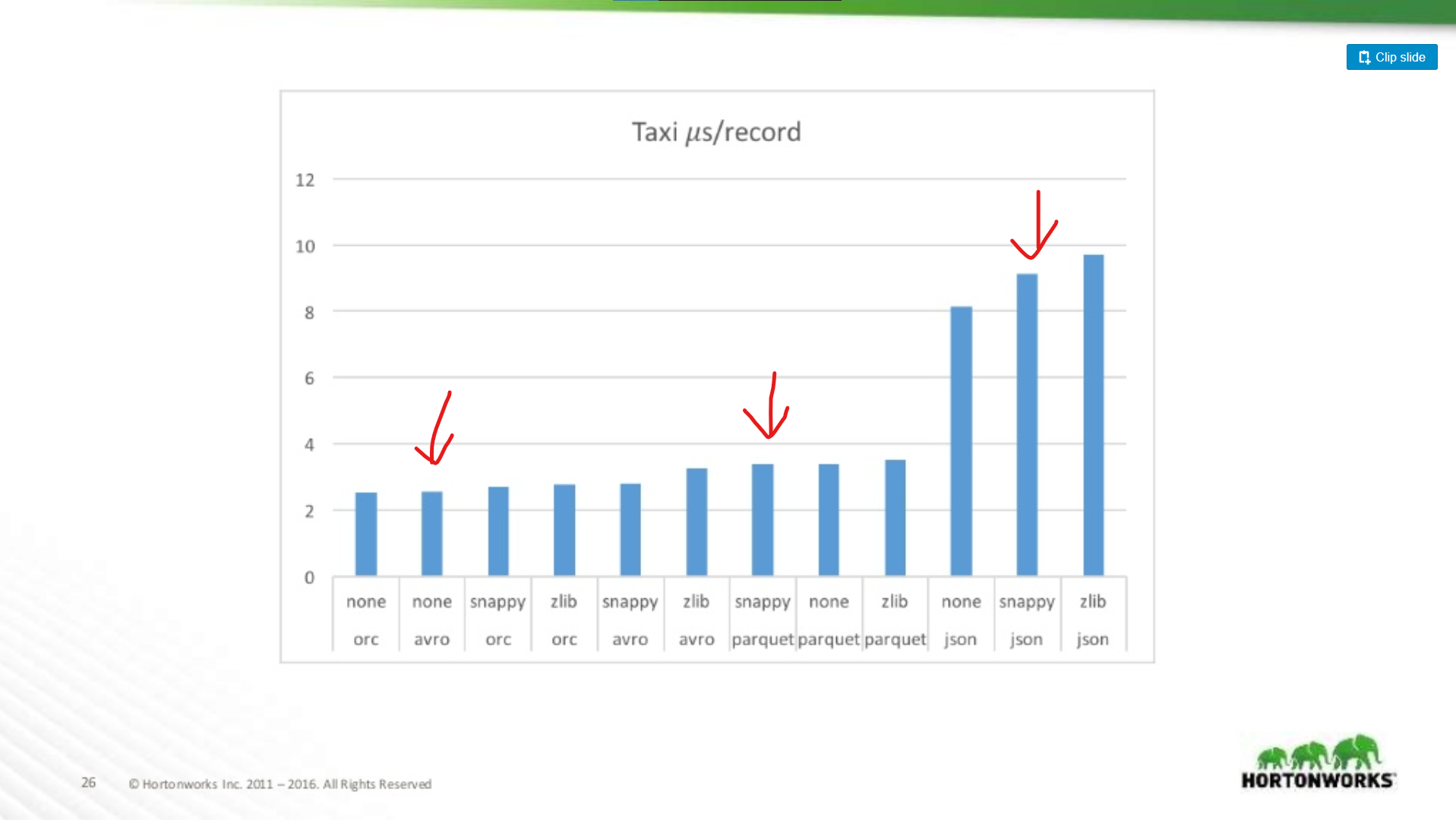
How much worse is Parquet for whole-record scans?
Here we compare the performance of Avro, JSON, and Parquet on a Taxi dataset containing ~18 columns. In this test they were reading entire records as part of a MapReduce job, this type of workload is worst-case Parquet performance, and here it almost matches Avro’s read performance.
At the other end of the spectrum they ran against a Github data dump which had an extreme 704 columns of data per record. Here we see a more significant advantage for Avro:
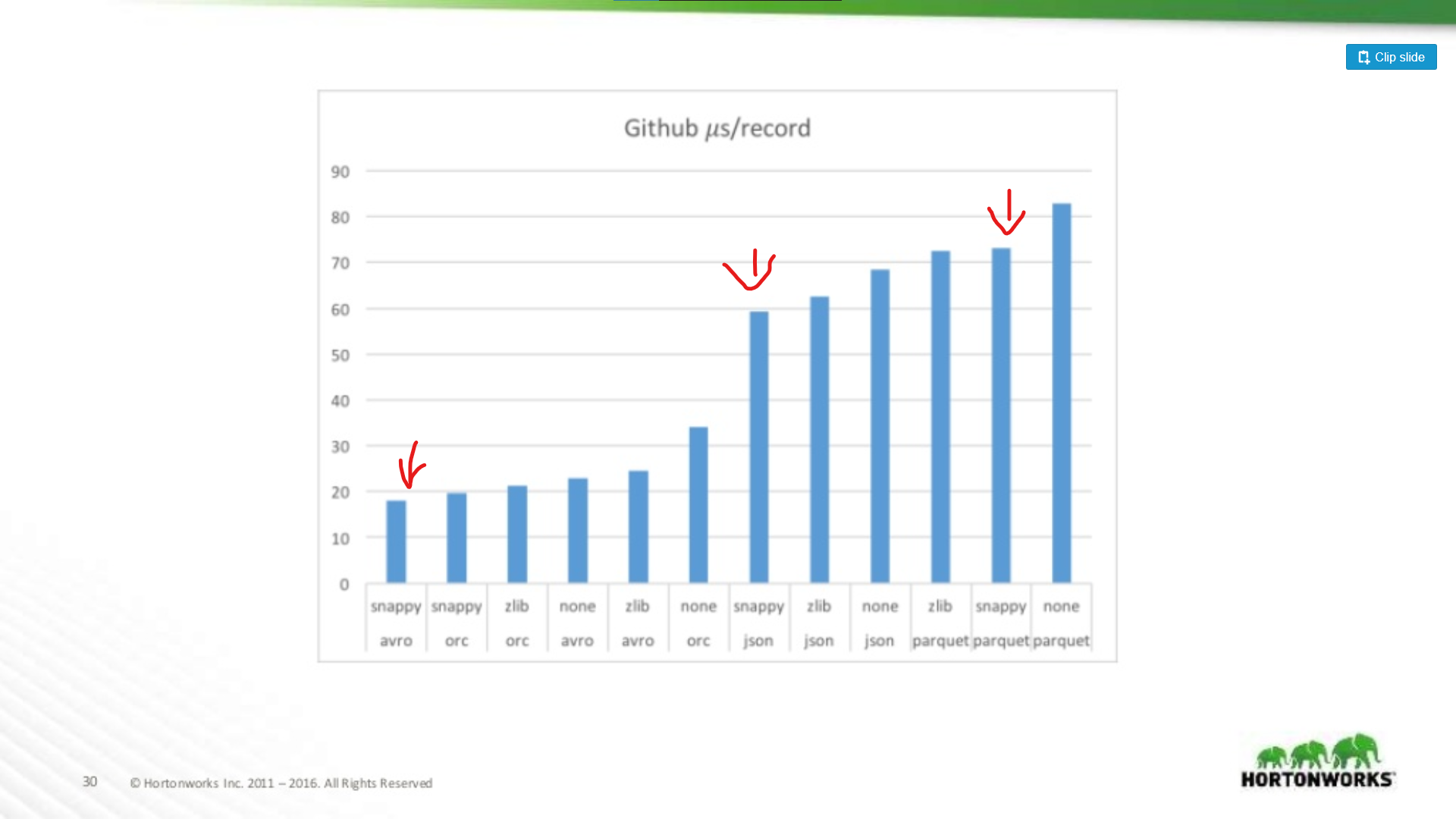
So the wider your dataset, the worse Parquet becomes for scanning entire records (which makes sense). This is an extreme example, most datasets are not 700 columns wide, for anything reasonable (< 100) Parquet read performance is close enough to Avro to not matter.
Parquet Investments
That said, mitigating Parquet’s negatives is a focus of significant investment. For example see this article from Cloudera on using Vectorization to limit the CPU overhead of parquet.
I still see some folks argue for Avro over Parquet even when full-record reads are slower in Avro. My opinion is that storage is cheap! CPUs are not. That same article shows a performance benefit of over 200x when reading only a single column from the file. That is truly significant, and as your dataset grows it will save a significant amount of compute resources.
Parquet is Probably The Right Choice Either Way
So if a dataset is just for MapReduce, should it go in Avro? No. It is tremendously helpful to be able to ‘peek’ inside a dataset and find quick information about it’s contents, besides, many MapReduce frameworks are adding predicate-pushdown to their parquet support. Parquet is not just for Analytics!
Even ignoring the runtime of your production jobs, let me outline some of my favorite ways to use Parquet outside of analytics workloads:
-
Data validation - need to do some rough counts to verify your data is complete? Such checks can be run in a few seconds with Parquet, even with a 1TB dataset.
-
Debugging - did your pipeline do the right thing? Did it add/remove/modify the right records? With parquet you can capture quick and easy information (such as all unique values of a column) in a few seconds without scanning the whole file.
-
Quick Metrics Extraction - want to record in your monitoring system a count of a subset of records in your dataset? Previously I captured this information by running a follow-up pipeline, but with Parquet it is a very fast query through either Hive or Spark SQL.
-
Less redundancy - Need a similar dataset for two different pipelines? Instead of building a distinct dataset for each, Parquet lets you just dynamically query a larger, comprehensive dataset without the penalties of scanning a whole file.
-
Analytics - Ok, I cheated and put it in anyway. Yes, Parquet is AMAZING for analytics, anyone running SQL queries will thank you for saving them hours a day in front of a SQL prompt when their queries run up to 1000x faster.
My Take: Just Use Parquet
While I think there are use cases for Avro over Parquet, those use-cases are fading.
- Industry tooling is coalescing around Parquet as a standard data storage format. See for Amazon Web Services for example. They’ll give you a usage data dump in Parquet (or CSV), and their EMR product provides special write-optimizations for Parquet. The same is not true of Avro.
- Frameworks like MapReduce are stepping aside in favor of more dynamic frameworks, like Spark, these frameworks favor a ‘dataframe’ style of programming where you only process the columns you need, and ignore the rest. This is great for Parquet.
- Parquet is just more flexible. While you may not always need to sparse-query a dataset, being able to is damn useful in a range of situations. You just don’t get to do that with Avro, CSV, or JSON.
