Is it 'MapReduce' or 'Map Reduce'?

image by Beatnik Photos
Hire me to supercharge your Hadoop and Spark projects
I help businesses improve their return on investment from big data projects. I do everything from software architecture to staff training. Learn More
MapReduce is a data processing methodology made popular by Hadoop. It describes a way that multiple computational units can work together to process a large scale dataset whilst acting independently and not depending on one another.
Should you call this technology ‘MapReduce’ or ‘Map Reduce’? It’s a question that is trivial, but common. Personally I’m very unreliable with how I describe the technology, sometimes I write ‘MapReduce’, and sometimes I write ‘Map Reduce’.
The short version is that the correct spelling is ‘MapReduce’. That is - all one word with R capitalized. You shouldn’t write ‘Map Reduce’ or ‘Map/Reduce’.
The Case for MapReduce vs Map Reduce
Google’s seminal paper from 2004 is titled MapReduce: Simplified Data Processing on Large Clusters. They’re very consistent about using MapReduce to describe the concept and nowhere in the paper do they split this into two words.
This is backed up by Google search traffic which shows MapReduce has a clear lead.
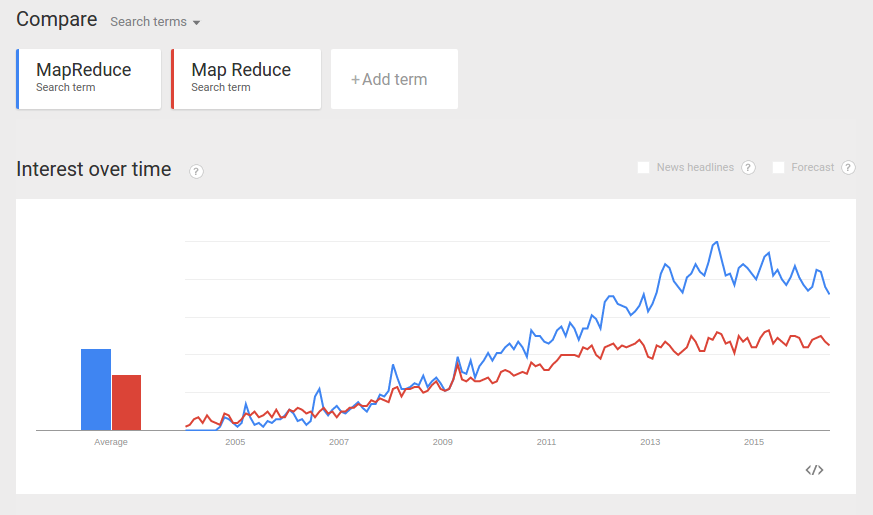 screenshot from Google Trends
screenshot from Google Trends
The Apache Hadoop website and big Hadoop vendors like Cloudera and Hortonworks refer to it as MapReduce also.
It’s Not All That Clear
However, outside of the Hadoop ecosystem naming is less clear. MongoDB has it’s own MapReduce implementation, but it is referred to as ‘Map-reduce’ (they don’t even capitalize the R! *Gasps*).
Even back in Hadoop-land not all content has settled on the MapReduce. There are several examples of places where folks are confused, or even use several different spellings.
Wrap-Up
It doesn’t really matter of course, but now you know – one MapReduce to rule them all.
While you’re here, check out my guide to MapReduce frameworks.
