A Beginners Guide to Hadoop

Hire me to supercharge your Hadoop and Spark projects
I help businesses improve their return on investment from big data projects. I do everything from software architecture to staff training. Learn More
The goal of this article is to provide a 10,000 foot view of Hadoop for those who know next to nothing about it. This article is not designed to get you ready for Hadoop development, but to provide a sound knowledge base for you to take the next steps in learning the technology.
First, some books
Hadoop now covers a lot of different topics, while this guide will provide you a gentle introduction I’ve compiled a good list of books that could help provide more guidance.
My guide to 15+ books for Hadoop.
Hadoop Intro
Hadoop is an Apache Software Foundation project that importantly provides two things:
- A distributed filesystem called HDFS (Hadoop Distributed File System)
- A framework and API for building and running MapReduce jobs
I will talk about these two things in turn. But first some links for your information:
- The Hadoop page on apache.org
- The Google File System (GFS) paper on which HDFS is based
- The Google MapReduce paper on which Hadoop’s MapReduce framework is based
- The Wikipedia page about hadoop
- Book: “Hadoop: The Definative Guide” on Amazon
HDFS
HDFS is structured similarly to a regular Unix filesystem except that data storage is distributed across several machines. It is not intended as a replacement to a regular filesystem, but rather as a filesystem-like layer for large distributed systems to use. It has in built mechanisms to handle machine outages, and is optimized for throughput rather than latency.
There are two and a half types of machine in a HDFS cluster:
- Datanode - where HDFS actually stores the data, there are usually quite a few of these.
- Namenode - the ‘master’ machine. It controls all the meta data for the cluster. Eg - what blocks make up a file, and what datanodes those blocks are stored on.
- Secondary Namenode - this is NOT a backup namenode, but is a separate service that keeps a copy of both the edit logs, and filesystem image, merging them periodically to keep the size reasonable.
- this is soon being deprecated in favor of the backup node and the checkpoint node, but the functionality remains similar (if not the same)

Data can be accessed using either the Java API, or the Hadoop command line client. Many operations are similar to their Unix counterparts. Check out the documentation page for the full list, but here are some simple examples:
list files in the root directory
hadoop fs -ls /list files in my home directory
hadoop fs -ls ./cat a file (decompressing if needed)
hadoop fs -text ./file.txt.gzupload and retrieve a file
hadoop fs -put ./localfile.txt /home/matthew/remotefile.txt
hadoop fs -get /home/matthew/remotefile.txt ./local/file/path/file.txtNote that HDFS is optimized differently than a regular file system. It is designed for non-realtime applications demanding high throughput instead of online applications demanding low latency. For example, files cannot be modified once written, and the latency of reads/writes is really bad by filesystem standards. On the flip side, throughput scales fairly linearly with the number of datanodes in a cluster, so it can handle workloads no single machine would ever be able to.
HDFS also has a bunch of unique features that make it ideal for distributed systems:
- Failure tolerant - data can be duplicated across multiple datanodes to protect against machine failures. The industry standard seems to be a replication factor of 3 (everything is stored on three machines).
- Scalability - data transfers happen directly with the datanodes so your read/write capacity scales fairly well with the number of datanodes
- Space - need more disk space? Just add more datanodes and re-balance
- Industry standard - Lots of other distributed applications build on top of HDFS (HBase, Map-Reduce)
- Pairs well with MapReduce - As we shall learn
HDFS Resources
For more information about the design of HDFS, you should read through apache documentation page. In particular the streaming and data access section has some really simple and informative diagrams on how data read/writes actually happen.
MapReduce
The second fundamental part of Hadoop is the MapReduce layer. This is made up of two sub components:
- An API for writing MapReduce workflows in Java.
- A set of services for managing the execution of these workflows.
The Map and Reduce APIs
The basic premise is this:
- Map tasks perform a transformation.
- Reduce tasks perform an aggregation.
In scala, a simplified version of a MapReduce job might look like this:
def map(lineNumber: Long, sentance: String) = {
val words = sentance.split()
words.foreach{word =>
output(word, 1)
}
}
def reduce(word: String, counts: Iterable[Long]) = {
var total = 0l
counts.foreach{count =>
total += count
}
output(word, total)
}Notice that the output to a map and reduce task is always a KEY, VALUE pair. You always output exactly one key, and one value.
The input to a reduce is KEY, ITERABLE[VALUE]. Reduce is called exactly once for each key output by the map phase. The ITERABLE[VALUE] is the set of all values output by the map phase for that key.
So if you had map tasks that output
map1: key: foo, value: 1
map2: key: foo, value: 32Your reducer would receive:
key: foo, values: [1, 32]Counter intuitively, one of the most important parts of a MapReduce job is what happens between map and reduce, there are 3 other stages; Partitioning, Sorting, and Grouping. In the default configuration, the goal of these intermediate steps is to ensure this behavior; that the values for each key are grouped together ready for the reduce() function. APIs are also provided if you want to tweak how these stages work (like if you want to perform a secondary sort).
Here’s a diagram of the full workflow to try and demonstrate how these pieces all fit together, but really at this stage it’s more important to understand how map and reduce interact rather than understanding all the specifics of how that is implemented.
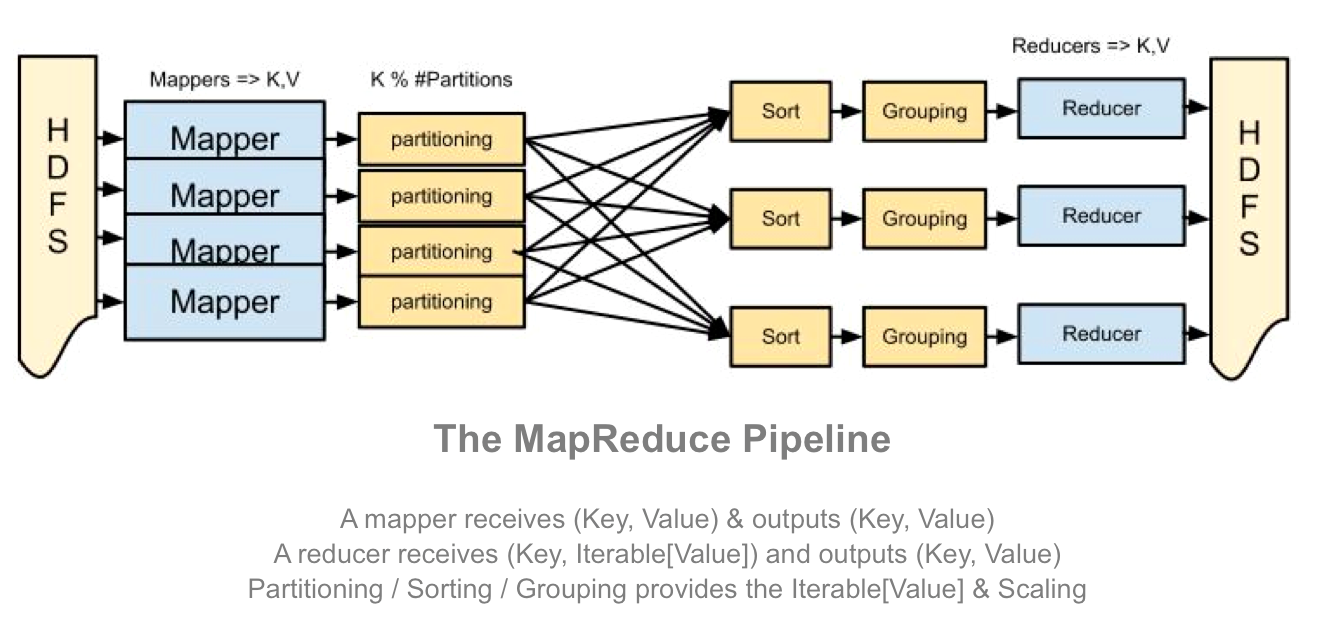
What’s really powerful about this API is that there is no dependency between any two of the same task. To do it’s job a map() task does not need to know about other map task, and similarly a single reduce() task has all the context it needs to aggregate for any particular key, it does not share any state with other reduce tasks.
Taken as a whole, this design means that the stages of the pipeline can be easily distributed to an arbitrary number of machines. Workflows requiring massive datasets can be easily distributed across hundreds of machines because there are no inherent dependencies between the tasks requiring them to be on the same machine.
MapReduce API Resources
If you want to learn more about MapReduce (generally, and within Hadoop) I recommend you read the Google MapReduce paper, the Apache MapReduce documentation, or maybe even the hadoop book. Performing a web search for MapReduce tutorials also offers a lot of useful information.
To make things more interesting, many projects have been built on top of the MapReduce API to ease the development of MapReduce workflows. For example Hive lets you write SQL to query data on HDFS instead of Java. There are many more examples, so if you’re interested in learning more about these frameworks, I’ve written a separate article about the most common ones.
The Hadoop Services for Executing MapReduce Jobs
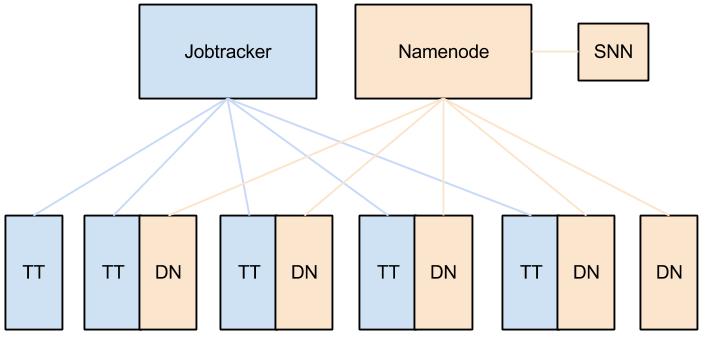
Hadoop MapReduce comes with two primary services for scheduling and running MapReduce jobs. They are the Job Tracker (JT) and the Task Tracker (TT). Broadly speaking the JT is the master and is in charge of allocating tasks to task trackers and scheduling these tasks globally. A TT is in charge of running the Map and Reduce tasks themselves.
When running, each TT registers itself with the JT and reports the number of ‘map’ and ‘reduce’ slots it has available, the JT keeps a central registry of these across all TTs and allocates them to jobs as required. When a task is completed, the TT re-registers that slot with the JT and the process repeats.
Many things can go wrong in a big distributed system, so these services have some clever tricks to ensure that your job finishes successfully:
- Automatic retries - if a task fails, it is retried N times (usually 3) on different task trackers.
- Data locality optimizations - if you co-locate a TT with a HDFS Datanode (which you should) it will take advantage of data locality to make reading the data faster
- Blacklisting a bad TT - if the JT detects that a TT has too many failed tasks, it will blacklist it. No tasks will then be scheduled on this task tracker.
- Speculative Execution - the JT can schedule the same task to run on several machines at the same time, just in case some machines are slower than others. When one version finishes, the others are killed.
Here’s a simple diagram of a typical deployment with TTs deployed alongside datanodes.
MapReduce Service Resources
For more reading on the JobTracker and TaskTracker check out Wikipedia or the Hadoop book. I find the apache documentation pretty confusing when just trying to understand these things at a high level, so again doing a web-search can be pretty useful.
Wrap Up
I hope this introduction to Hadoop was useful. There is a lot of information on-line, but I didn’t feel like anything described Hadoop at a high-level for beginners.
The Hadoop project is a good deal more complex and deep than I have represented and is changing rapidly. For example, an initiative called MapReduce 2.0 provides a more general purpose job scheduling and resource management layer called YARN, and there is an ever growing range of non-MapReduce applications that run on top of HDFS, such as Cloudera Impala.
If you breezed through this article and the related readings and you’re ready and eager to write some MapReduce jobs, you might want to check out my article on MapReduce frameworks. I also plan on creating a second article on how to start working with Hadoop as a beginner, when I do I will update this article with a link.
Please get in touch in the comments or on twitter with any questions!
