Hadoop Python MapReduce Tutorial for Beginners

Hire me to supercharge your Hadoop and Spark projects
I help businesses improve their return on investment from big data projects. I do everything from software architecture to staff training. Learn More
This article originally accompanied my tutorial session at the Big Data Madison Meetup, November 2013.
The goal of this article is to:
- introduce you to the hadoop streaming library (the mechanism which allows us to run non-jvm code on hadoop)
- teach you how to write a simple map reduce pipeline in Python (single input, single output).
- teach you how to write a more complex pipeline in Python (multiple inputs, single output).
There are other good resouces online about Hadoop streaming, so I’m going over old ground a little. Here are some good links:
- Hadoop Streaming official Documentation
- Michael Knoll’s Python Streaming Tutorial
- An Amazon EMR Python streaming tutorial
If you are new to Hadoop, you might want to check out my beginners guide to Hadoop before digging in to any code (it’s a quick read I promise!).
Setup
I’m going to use the Cloudera Quickstart VM to run these examples.
Once you’re booted into the quickstart VM we’re going to get our dataset. I’m going to use the play-by-play nfl data by Brian Burke. To start with we’re only going to use the data in his Git repository.
Once you’re in the cloudera VM, clone the repo:
cd ~/workspace
git clone https://github.com/eljefe6a/nfldata.gitTo start we’re going to use stadiums.csv. However this data was encoded in Windows (grr) so has ^M line separators instead of new lines \n. We need to change the encoding before we can play with it:
cd workspace/nfldata
cat stadiums.csv # BAH! Everything is a single line
dos2unix -l -n stadiums.csv unixstadiums.csv
cat unixstadiums.csv # Hooray! One stadium per lineHadoop Streaming Intro
The way you ordinarily run a map-reduce is to write a java program with at least three parts.
- A Main method which configures the job, and lauches it
- set # reducers
- set mapper and reducer classes
- set partitioner
- set other hadoop configurations
- A Mapper Class
- takes K,V inputs, writes K,V outputs
- A Reducer Class
- takes K, Iterator[V] inputs, and writes K,V outputs
Hadoop Streaming is actually just a java library that implements these things, but instead of actually doing anything, it pipes data to scripts. By doing so, it provides an API for other languages:
- read from STDIN
- write to STDOUT
Streaming has some (configurable) conventions that allow it to understand the data returned. Most importantly, it assumes that Keys and Values are separated by a \t. This is important for the rest of the map reduce pipeline to work properly (partitioning and sorting). To understand why check out my intro to Hadoop, where I discuss the pipeline in detail.
Running a Basic Streaming Job
It’s just like running a normal mapreduce job, except that you need to provide some information about what scripts you want to use.
Hadoop comes with the streaming jar in it’s lib directory, so just find that to use it. The job below counts the number of lines in our stadiums file. (This is really overkill, because there are only 32 records)
hadoop fs -mkdir nfldata/stadiums
hadoop fs -put ~/workspace/nfldata/unixstadiums.csv nfldata/stadiums/
hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.4.0.jar \
-Dmapred.reduce.tasks=1 \
-input nfldata/stadiums \
-output nfldata/output1 \
-mapper cat \
-reducer "wc -l"
# now we check our results:
hadoop fs -ls nfldata/output1
# looks like files are there, lets get the result:
hadoop fs -text nfldata/output1/part*
# => 32A good way to make sure your job has run properly is to look at the jobtracker dashboard. In the quickstart VM there is a link in the bookmarks bar.
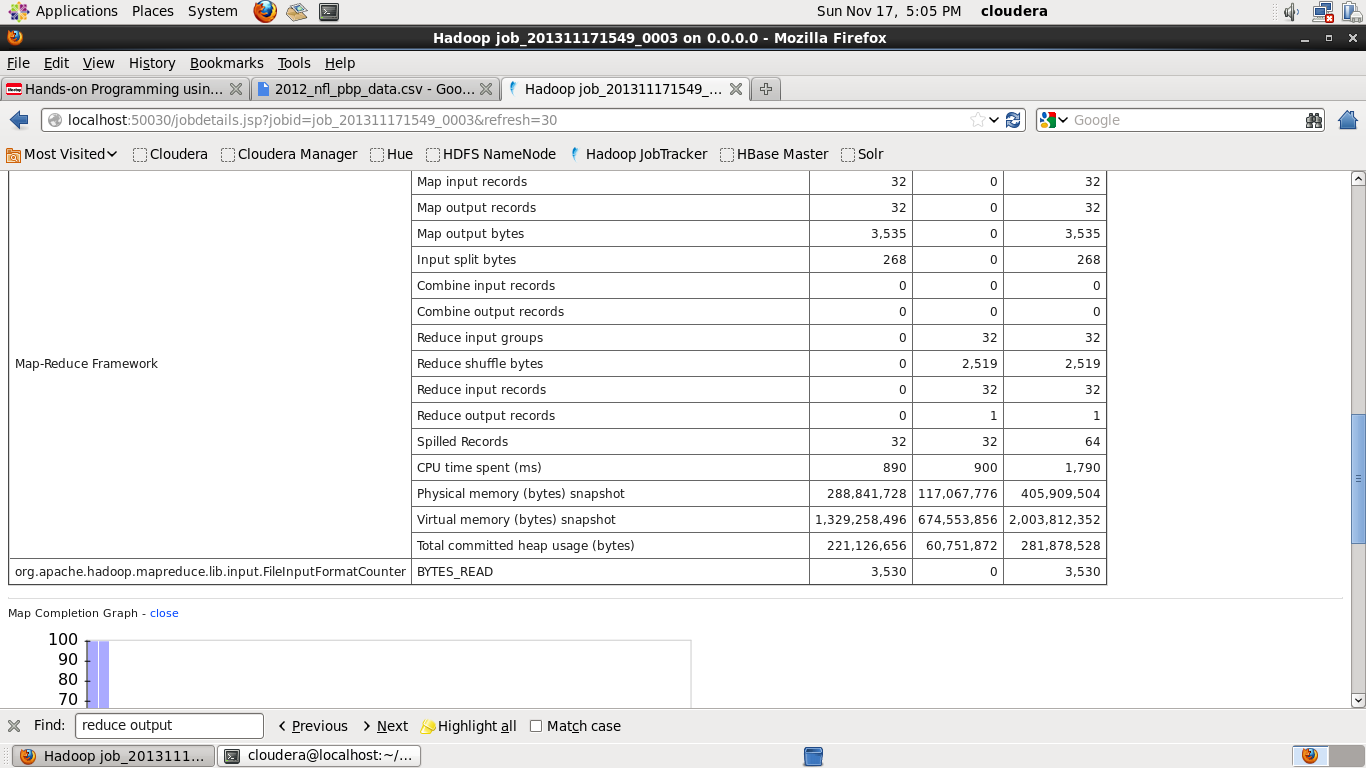
You should see your job in the running/completed sections, clicking on it brings up a bunch of information. The most useful data on this page is under the Map-Reduce Framework section, in particular look for stuff like:
- Map Input Records
- Map Output Records
- Reduce Output Records
In our example, input records are 32 and output records is 1:
A Simple Example in Python
Looking in columns.txt we can see that the stadium file has the following fields:
Stadium (String) - The name of the stadium
Capacity (Int) - The capacity of the stadium
ExpandedCapacity (Int) - The expanded capacity of the stadium
Location (String) - The location of the stadium
PlayingSurface (String) - The type of grass, etc that the stadium has
IsArtificial (Boolean) - Is the playing surface artificial
Team (String) - The name of the team that plays at the stadium
Opened (Int) - The year the stadium opened
WeatherStation (String) - The name of the weather station closest to the stadium
RoofType (Possible Values:None,Retractable,Dome) - The type of roof in the stadium
Elevation - The elevation of the stadiumLets use map reduce to find the number of stadiums with artificial and natrual playing surfaces.
The pseudo-code looks like this:
def map(line):
fields = line.split(",")
print(fields.isArtificial, 1)
def reduce(isArtificial, totals):
print(isArtificial, sum(totals))You can find the finished code in my Hadoop framework examples repository.
Important Gotcha!
The reducer interface for streaming is actually different than in Java. Instead of receiving reduce(k, Iterator[V]), your script is actually sent one line per value, including the key.
So for example, instead of receiving:
reduce('TRUE', Iterator(1, 1, 1, 1))
reduce('FALSE', Iterator(1, 1, 1))It will receive:
TRUE 1
TRUE 1
TRUE 1
TRUE 1
FALSE 1
FALSE 1
FALSE 1This means you have to do a little state tracking in your reducer. This will be demonstrated in the code below.
To follow along, check out my git repository (on the virtual machine):
cd ~/workspace
git clone https://github.com/rathboma/hadoop-framework-examples.git
cd hadoop-framework-examplesMapper
import sys
for line in sys.stdin:
line = line.strip()
unpacked = line.split(",")
stadium, capacity, expanded, location, surface, turf, team, opened, weather, roof, elevation = line.split(",")
results = [turf, "1"]
print("\t".join(results))Reducer
import sys
# Example input (ordered by key)
# FALSE 1
# FALSE 1
# TRUE 1
# TRUE 1
# UNKNOWN 1
# UNKNOWN 1
# keys come grouped together
# so we need to keep track of state a little bit
# thus when the key changes (turf), we need to reset
# our counter, and write out the count we've accumulated
last_turf = None
turf_count = 0
for line in sys.stdin:
line = line.strip()
turf, count = line.split("\t")
count = int(count)
# if this is the first iteration
if not last_turf:
last_turf = turf
# if they're the same, log it
if turf == last_turf:
turf_count += count
else:
# state change (previous line was k=x, this line is k=y)
result = [last_turf, turf_count]
print("\t".join(str(v) for v in result))
last_turf = turf
turf_count = 1
# this is to catch the final counts after all records have been received.
print("\t".join(str(v) for v in [last_turf, turf_count]))You might notice that the reducer is significantly more complex then the pseudocode. That is because the streaming interface is limited and cannot really provide a way to implement the standard API.
As noted, each line read contains both the KEY and the VALUE, so it’s up to our reducer to keep track of Key changes and act accordingly.
Don’t forget to make your scripts executable:
chmod +x simple/mapper.py
chmod +x simple/reducer.pyTesting
Because our example is so simple, we can actually test it without using hadoop at all.
cd streaming-python
cat ~/workspace/nfldata/unixstadiums.csv | simple/mapper.py | sort | simple/reducer.py
# FALSE 15
# TRUE 17Looking good so far!
Running with Hadoop should produce the same output.
hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.4.0.jar \
-mapper mapper.py \
-reducer reducer.py \
-input nfldata/stadiums \
-output nfldata/pythonoutput \
-file simple/mapper.py \
-file simple/reducer.py
# ...twiddle thumbs for a while
hadoop fs -text nfldata/pythonoutput/part-*
FALSE 15
TRUE 17A Complex Example in Python
Check out my advanced python MapReduce guide to see how to join two datasets together using python.
Python MapReduce Book
While there are no books specific to Python MapReduce development the following book has some pretty good examples:

Mastering Python for Data Science
While not specific to MapReduce, this book gives some examples of using the Python 'HadoopPy' framework to write some MapReduce code. It's also an excellent book in it's own right.
